We present AVE-PM, the first dataset for audio-visual event localization in portrait mode short videos and present the challenge of the research on this emerging video format.
While existing datasets for audio-visual event localization (AVEL) predominantly comprise landscape-oriented long videos with simple audio context, short videos have become the primary format of online video content due to the the proliferation of smartphones.
Short videos are characterized by portrait-oriented framing and layered audio compositions (e.g., overlapping sound effects, voiceovers, and music), which brings unique challenges unaddressed by conventional AVEL datasets.
To this end, we introduce AVE-PM, the first AVEL dataset specifically designed for portrait mode short videos, comprising 25,335 clips that span 86 fine-grained categories with frame-level annotations and sample-level labels indicating background music (BGM) presence. Our cross-mode evaluation reveals that state-of-the-art AVEL models suffer an average 18.66% performance drop during cross-mode evaluations.
Further analysis identifies two critical challenges: (1) Spatial bias in PM videos, where PM videos exhibit distinct object distribution patterns, with standard center cropping degrading performance on PM videos. (2) Audio complexity, as BGM interference in short videos compromises audio reliability. We explore audio signal processing strategies to remove the background musics in short videos. Results show that self NMF method boosts three AVEL models by up to +2.50% in accuracy.
Our work establishes a foundational benchmark and provides empirically validated strategies for advancing AVEL research in the mobile-centric video era.
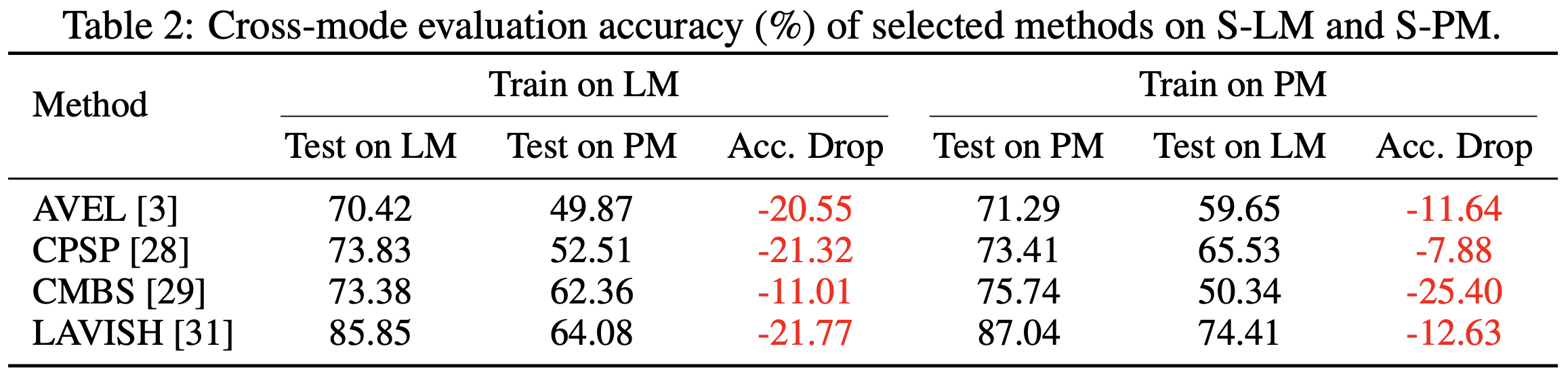
The cross-mode evaluation results show that state-of-the-art AVEL models suffer an average 18.66% performance drop during cross-mode evaluations, indicating that the performance of AVEL models is significantly affected by the mode of the input video.
What is the influence of spatial bias between portrait mode and landscape mode videos?
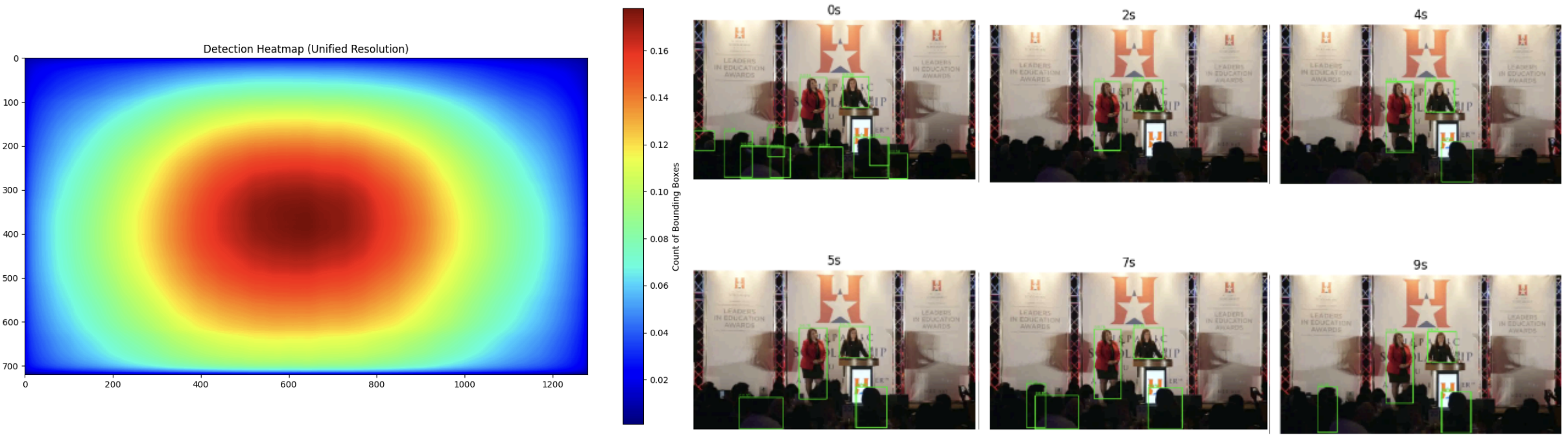

We measure the influence of spatial bias in the video domain by visualizing YOLOv5 bounding box distributions, which reveals that portrait mode videos exhibit more concentrated object information, primarily located in the central-lower portion of the frame, whereas landscape mode videos display objects that occupy a smaller proportion of the frame, being tightly focused around the very center.
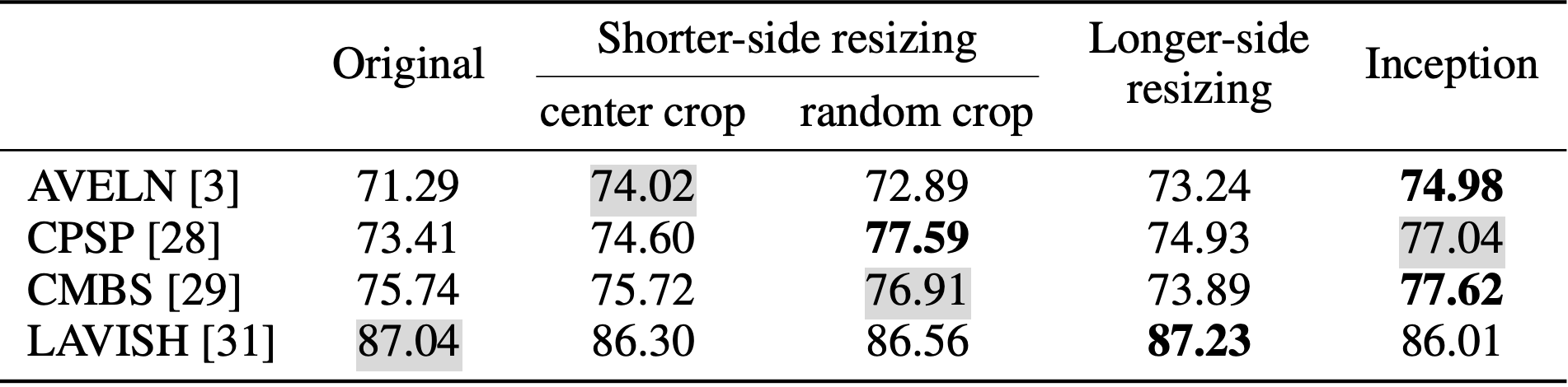
VGG-based methods achieve their best performance with Inception-style resizing (74.98% for AVELN and 77.62% for CMBS) or shorter-side resizing with random cropping (77.59% for CPSP), indicating that random operations enhance robustness to aspect ratio distortions. In contrast, the Vision Transformer-based LAVISH performs best with aspect ratio-preserving longer-side resizing (87.23%), outperforming its original square resizing (87.04%) and revealing ViTs' sensitivity to geometric integrity.
We adopt three audio processing methods to remove the background music in short videos:

An illustration of the spectrum of the audio signal before and after removing the background music.

The results demonstrate varying impacts of BGM removal techniques across different models. First, the effectiveness of preprocessing strategies differs significantly depending on the baseline method. For instance, Template NMF achieves the highest accuracy improvement for AVELN (75.43%, +4.14% over no removal) but slightly degrades CMBS performance (75.40%, -0.34%), while Adaptive Filtering benefits CPSP the most (75.61%, +2.20%) yet underperforms for CMBS (74.50%, -1.24%). Second, among the three preprocessing strategies, Self NMF is the only approach that consistently enhances performance across all models, improving AVELN (73.79%, +2.50%), CPSP (74.41%, +1.00%), and CMBS (77.36%, +1.62%).
| Original Event | BGM Template | BGM Removed |
| Original Event | Target Event Template | BGM Removed |
| Original Event | BGM Template | BGM Removed |
In this paper, we introduce the Audio-visual Event in Portrait Mode (AVE-PM) dataset, the first dataset dedicated to audio-visual event localization in portrait mode short videos.
Through comprehensive experiments, we demonstrated that existing AVEL models struggle to generalize across video modes, revealing a significant domain gap. We also identify the key differences between landscape mode and portrait mode videos, such as spatial bias and audio complexity, highlighting the need for specialized approaches.
We make initial attempts to investigate optimal preprocessing techniques for both video and audio modalities.
We hope AVE-PM provides a foundation for future research, encouraging further research on portrait mode videos.